FAQ
There is a model that I want to use; can SoftNeuro reduce its inference time?
To perform inference with SoftNeuro, the model has to be converted to DNN format. Once a model has been converted to DNN format, it can be speed-optimized and run on any platform that is supported by SoftNeuro. A model converter tool is provided for converting TensorFLow(.pb), Keras(.h5), and ONNX(.onnx) models to DNN format. For other formats, it may be possible to convert them first to ONNX format and then to DNN format. Please refer to the CLI Tool Manual for details on how to use the converter.
How much speed improvement can we achieve?
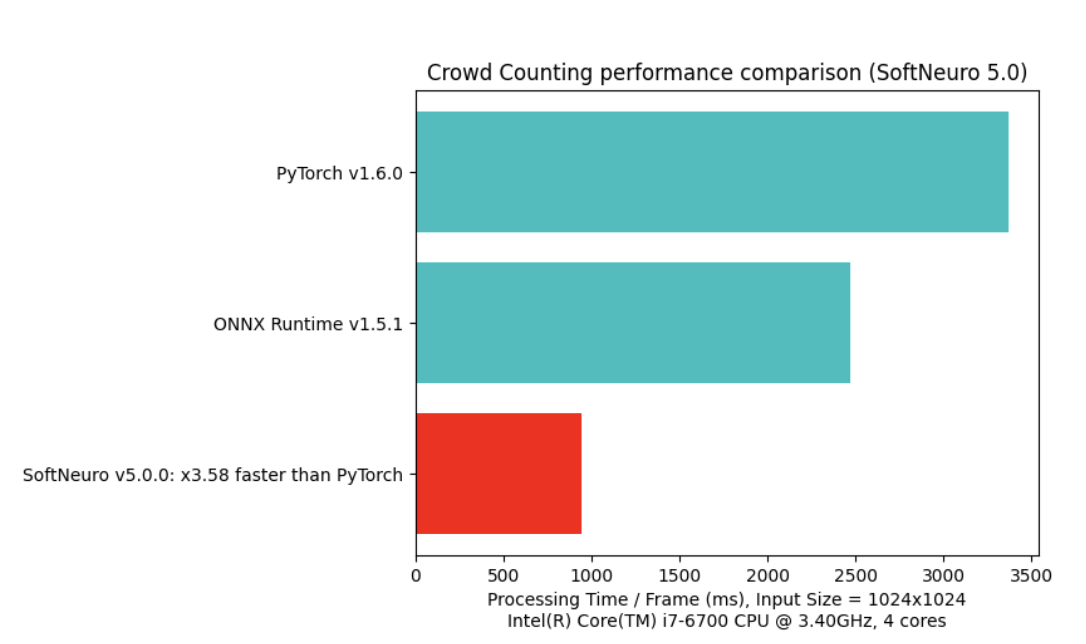
The effectiveness of speed optimization depends heavily on the model, target environment and available resources. Optimization settings (such as the use of model quantization) can also change the inference speed. For your reference we include below a comparison of SoftNeuro's inference speed with mainstream frameworks, with selected models and platforms.
Is it possible to use custom layers?
The standard version of SoftNeuro does not support custom layers designed using TensorFLow and layers that are not supported by the standard converter. However, by implementing custom layers in C language according to SoftNeuro's API specification, it is possible to add custom layers that are compatible with SoftNeuro. If you want support for custom layers, please contact us regarding the details on supporting them.
What kind of options are available for commercial licensing?
At the moment we are working on the details for subscription-based commercial licensing. If you are interested in using SoftNeuro for commercial applications, feel free to contact us.