FAQ
利用したいモデルがあるのですが、SoftNeuroで高速化できますか?
SoftNeuroで推論を実行するためには、DNN形式に変換する必要があります。
一度DNNファイルに変換すればサポートされているどのプラットフォームでもSoftNeuroで高速化を試すことができるようになります。
学習済みモデルの形式がTensorFLow(.pb), Keras(.h5), ONNX(.onnx)形式であれば、モデル変換用のコンバータが用意されています。
また、それ以外の形式でもONNXに一度変換することでdnnファイルに変換することができる場合があります。
コンバータの詳細な利用方法についてはCLIツールのマニュアルをご参照ください。
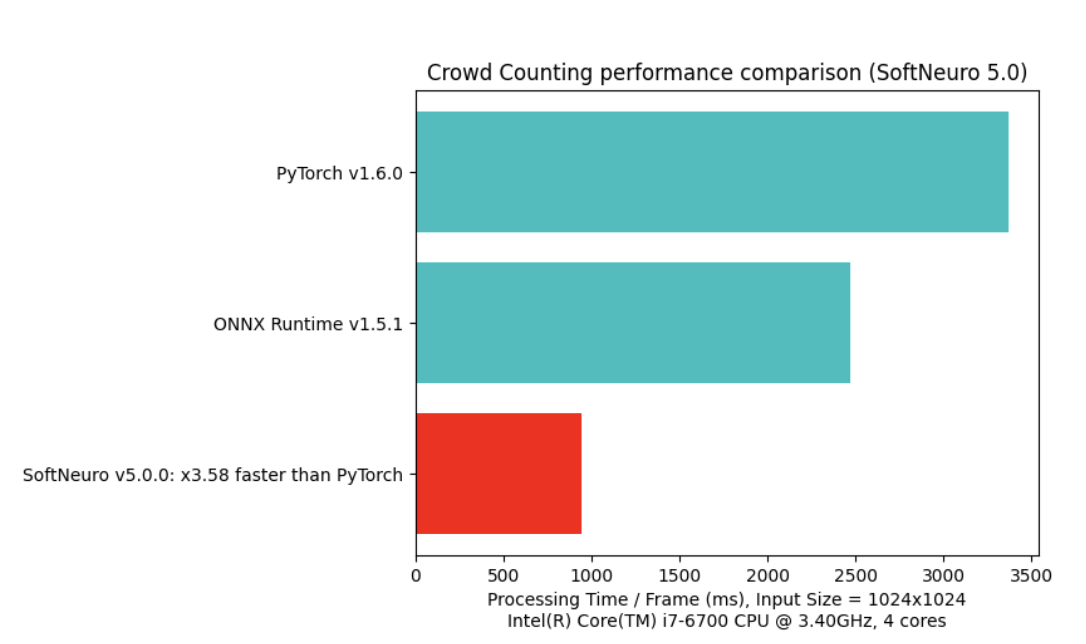
どのくらい速くなりますか?
SoftNeuroによる高速化の効果はモデルや実行環境で利用可能な計算機リソースによって大きく異なります。
また、最適化の設定(推論時に量子化を行うか等)によっても変化します。
参考値として、特定の環境下におけるSoftNeuroと代表的なフレームワークを利用した速度測定の結果を掲載いたします。
カスタムレイヤーを利用することはできますか?
標準のSoftNeuroには、TensorFlow等で作成されたカスタムレイヤーなどの
標準コンバータが対応していないレイヤーを変換して利用する機能がありません。
ただし、SoftNeuroの仕様に合わせた形式でカスタムレイヤーの機能をC言語で実装していただくことで、
SoftNeuroが該当のカスタムレイヤーの処理を実行することが可能となる、カスタムレイヤーの追加機能がございます。
カスタムレイヤー追加機能の詳細な利用方法については、お問い合わせ窓口までご連絡いただきますようお願いいたします。
商用利用のライセンスにはどんなプランがありますか?
サブスクリプション形式でご利用いただく際のライセンスプランの詳細は現在検討中です。
商用利用をご検討の際は、お問い合わせ窓口までご連絡いただきますようお願いいたします。